目标网站:https://maoyan.com/board/1
百度字体工具: http://fontstore.baidu.com/static/editor/index.html
爬取目标:电影票房数据
确定目标数据位置
通过检查网页元素发现猫眼的票房数据是方框乱码:
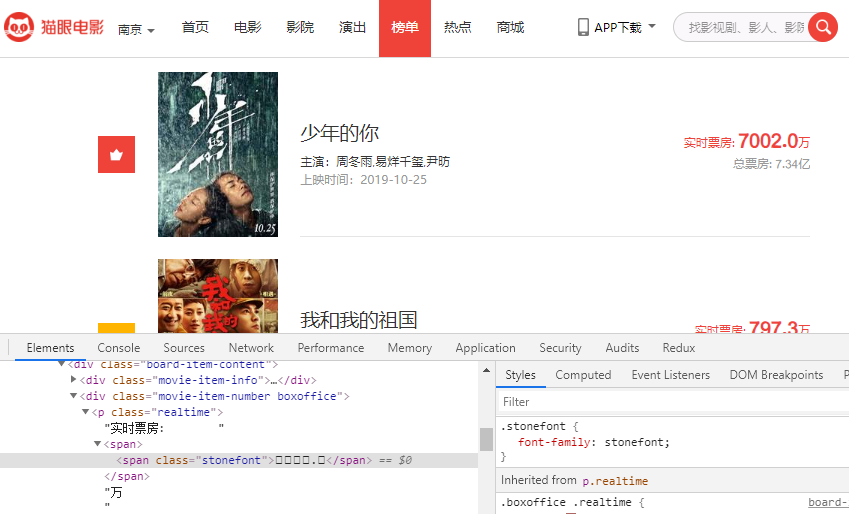
而查看网页源码时发现票房数据是一串类似编码的字符串:
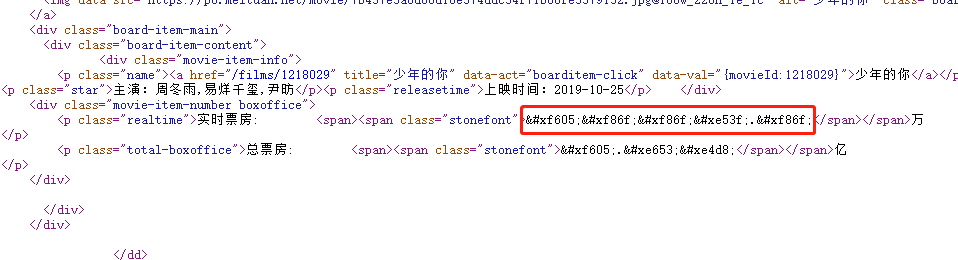
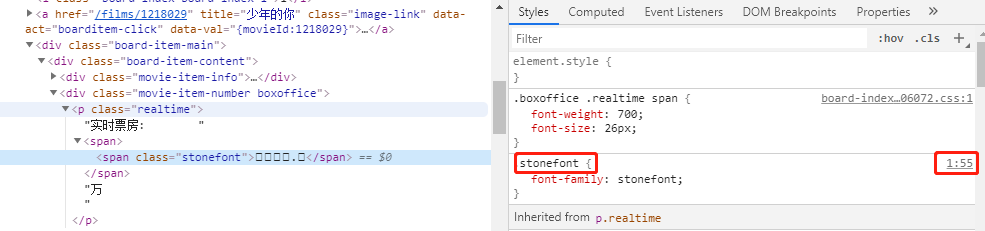
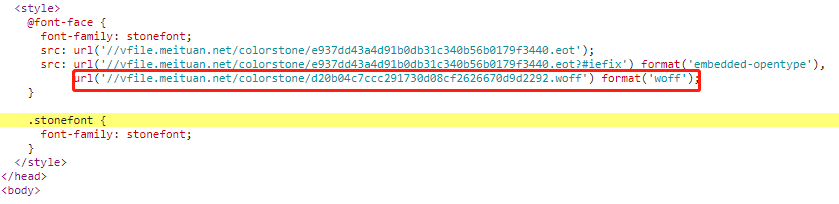
这是因为这个span标签添加了字体样式“stonefont”,源码中的编码其实是字形的编码。通过点击这个元素可以在右侧看到字体文件,点击进入字体文件所在的位置可以下载woff格式的字体文件。
字体文件解析
借助百度字体工具可以打开字体文件,发现不同的字形对应不同的编码:
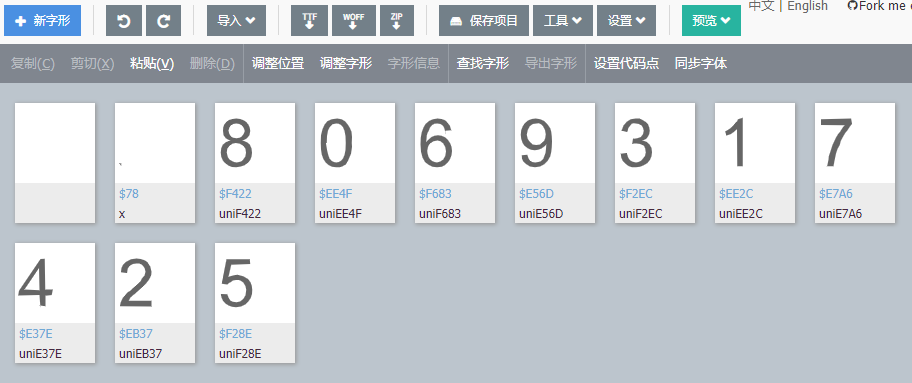
至此就能得到编码和字符的对应关系:
# 字形编码与数字字符对应关系
relation = {
'uniEE4F': '0',
'uniEE2C': '1',
'uniEB37': '2',
'uniF2EC': '3',
'uniE37E': '4',
'uniF28E': '5',
'uniF683': '6',
'uniE7A6': '7',
'uniF422': '8',
'uniE56D': '9',
}
然而通过刷新网页发现字体文件是动态变化的,也就是说编码和字符的对应关系是动态变化的,下图是第二个字体文件的内容:
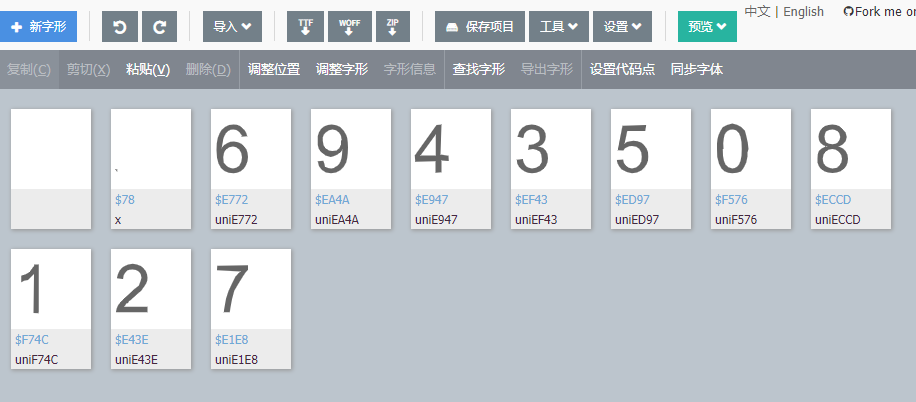
虽然编码不固定,但是通过观察可以发现字形是基本不变的,可以通过比对找出两个字体文件相同的字形,那么相同字形对应的编码就应该代表同一个字符。接下来分析字体文件,使用fontTools库将woff字体文件转化为XML文件:
from fontTools.ttLib import TTFont
font1 = TTFont('font/1.woff')
font1.saveXML('font/1.xml')
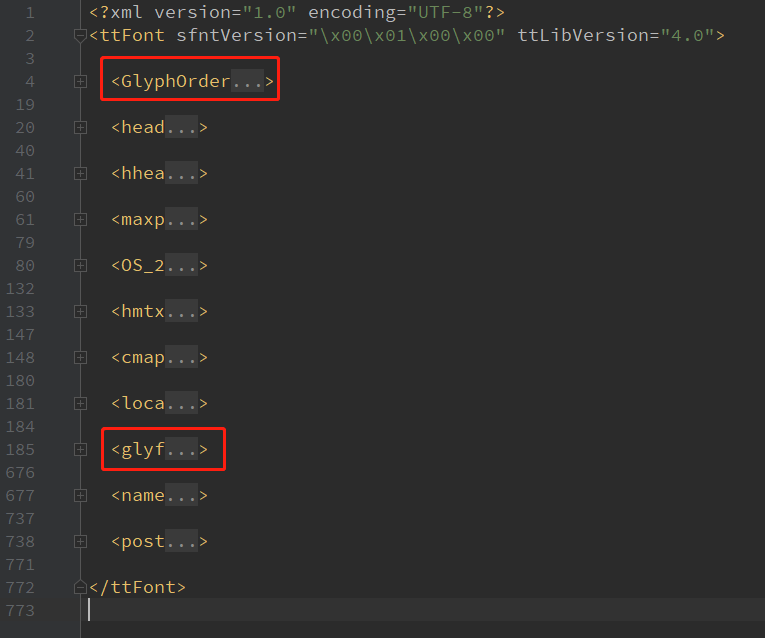
XML文件结构如下图,其中重点是GlyphOrder部分和glyf部分:GlyphOrder是字形编码列表,glyf则是各个字形对象的内容(用轮廓坐标描述)。
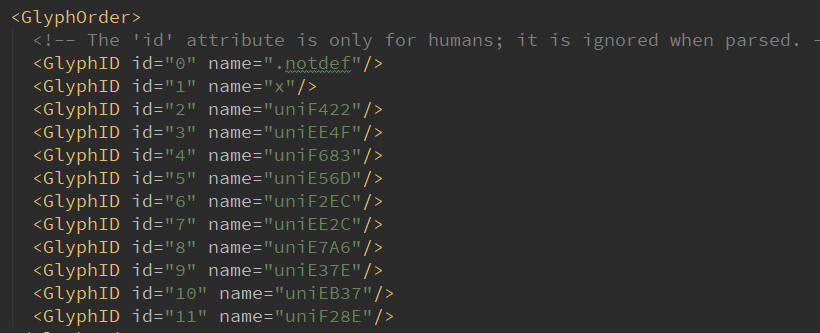
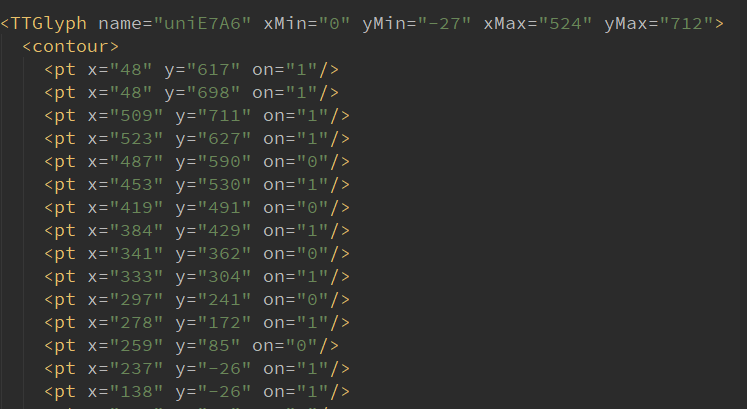
这里取的字形编码uniE7A6在第一个字体文件中表示字符7,在第二个字体文件中表示7的编码是uniE1E8,它对应的字形对象是:
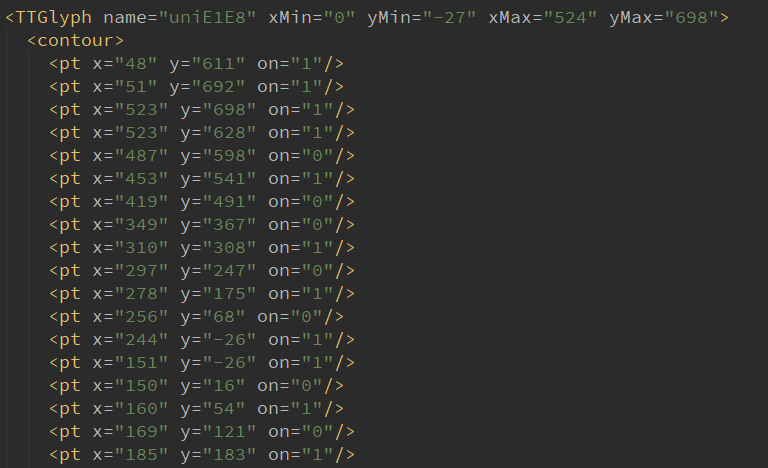
我们发现两个字形对象坐标并不完全一致,但是坐标的差值是在一定误差范围内的,通过比对这两组坐标,可以确定它们是否是代表同一个字符:
def compare_coordinate(a, b):
for i in range(10):
if abs(a[i][0] - b[i][0]) > 80 or abs(a[i][1] - b[i][1]) > 80:
return False
return True
动态解析字形编码与字符的关系
我们通过解析第一个字体文件得到了字形编码和字符的关系,接下来每次访问猫眼票房页面都能得到一个动态的字体文件,通过对比两个字体文件的字形对象可以得到字形编码的对应关系,进一步得到动态字体文件字形编码和字符的对应关系:
# 字体1的各字形编码
font1 = TTFont('font/1.woff')
name1_list = font1.getGlyphOrder()[2:]
# 字体2的各字形编码
font2 = TTFont('font/2.woff')
name2_list = font2.getGlyphOrder()[2:]
relation_new = dict()
for name1 in name1_list:
obj1 = font1['glyf'][name1] # 字体1的字形对象
coordinate1 = obj1.coordinates # 字形对象对应的坐标组
for name2 in name2_list:
obj2 = font2['glyf'][name2] # 字体2的字形对象
coordinate2 = obj2.coordinates # 字形对象对应的坐标组
if compare_coordinate(coordinate1, coordinate2):
relation_new[name2] = relation[name1]
结果:
